About Me
I am a Ph.D. student at Cornell CIS advised by Prof. Kuan Fang. My research interest is to develop sample-efficient robot learning methods to acquire robust and versatile behaviors. I obtained my Bachelor’s degree from UC Berkeley. During my time there as an undergraduate student, I was fortunate enough to have worked with Laura Smith, Prof. Sergey Levine, and Dr. Allen Yang.
Interests
- Artificial Intelligence
- Robot Learning
Education
PhD Computer Science
Cornell University
BA Computer Science
UC Berkeley
Featured Publications

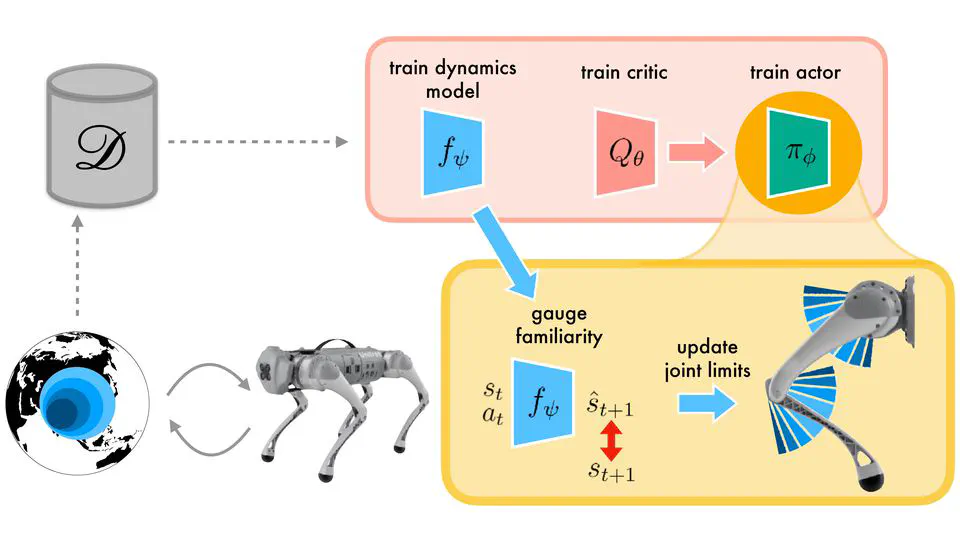
Recent Publications