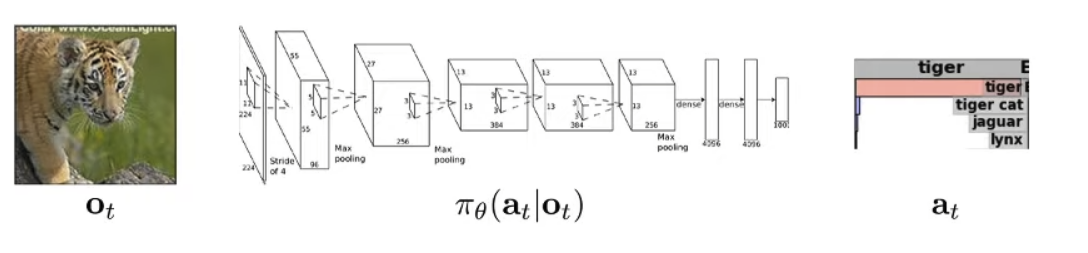
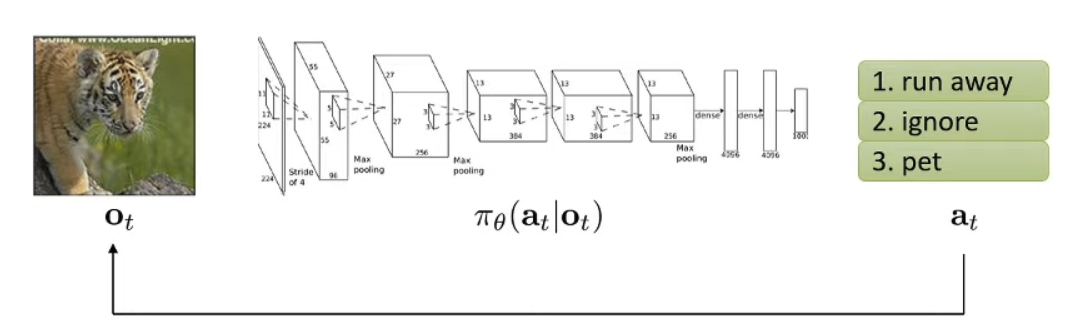
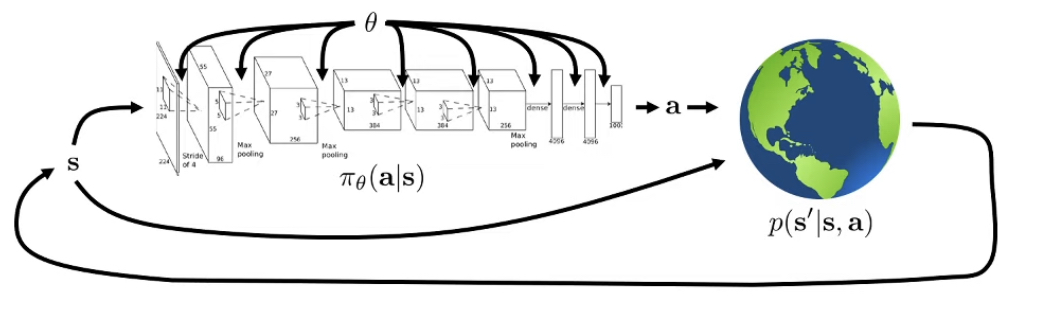
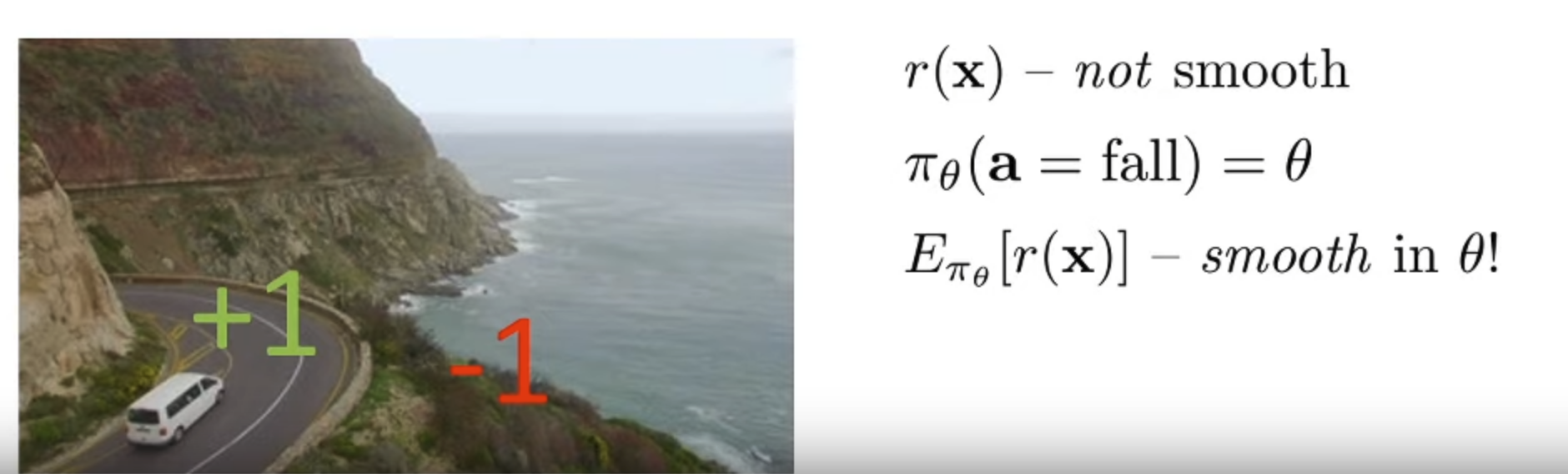We are actually trying to learn a distribution of action a given the observation o, where θ is the parameter of the distribution policy π. we add subscript t to each term to denote the index in the time-serie since we know in RL that actions are usually correlated.
Sometimes instead of πθ(at∣ot) we will see πθ(at∣st).
Difference - can use observation to infer state, but sometimes (in this example, car in front of the cheetah) the observation does not give enough information to let us infer state.
State is the true configuration of the system and observation is something that results from the state which may or may not be enough to deduce the state
🔥
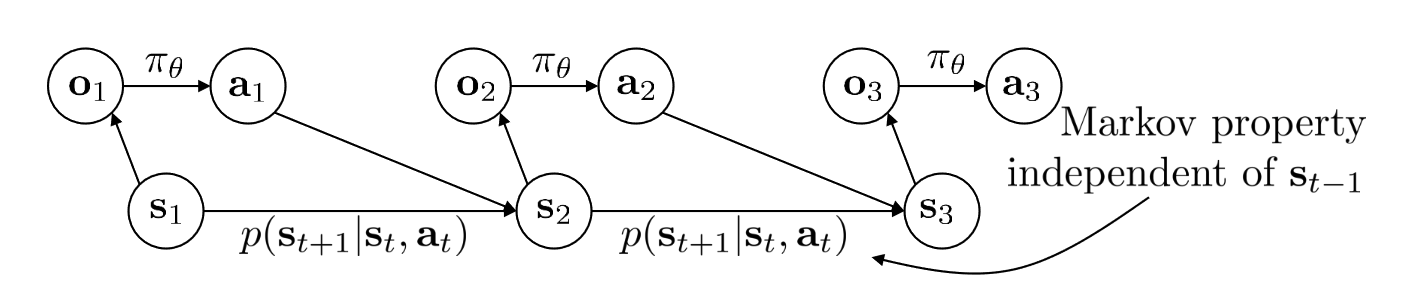
The state is usually assumed to be an Markovian state
Markov property is very important property ⇒ If you want to change the future you just need to focus on current state and your current action
However, is your future state independent of your past observation? In general, observations do not satisfy Markov property
Many RL algorithms in this course requires Markov property
Side note on notation
RL world (Richard Bellman)
Robotics (Lev Pontryagin)
st state
xt state
at action
ut action
r(s,a) reward
c(x,u) cost =−r(x,u)
In general, we want to minimize:
θminEs1:T,a1:T[t∑c(st,at)]
We can either write the funciton c as c or r, which stands for either (minimize) cost or (maximize) reward
🔥
Notice that we want to maximize the reward (or minimize the cost) under the expectation of the states that we are going to encounter in production / test environment, not training states.
Definition of Markov Chain
M={S,T}
S→state spaces∈S→state (discrete or continuous)T→transition operator described by P(st+1∣st)
The transition “operator”?
let μt,i=P(st=i),then μt is a vector of probabilities,let Ti,j=P(st+1=i∣si=j),then μt+1=Tμt
Definition of Markov Decision Process
M={S,A,T,r}
S→action space,s∈S→state (discrete or continuous)A→action space,a∈A→action (discrete or continuous)r:S×A→R→
T→transitional operator (now a tensor)μt,i=P(st=i),ξt,k=P(at=k),So Ti,j,k=P(st+1=i∣st=j,at=k)μt+1,i=j,k∑Ti,j,kμt,jξt,k
Partially Observed Markov Decision Process
M={S,A,O,T,ξ,r}S→state spaces∈S→state (discrete or continuous)A→action spacea∈A→action (discrete or continuous)O→observation spaceo∈O→observation (discrete or continuous)T→transition operationξ→emission probability P(ot∣st)r:S×A→R⟶reward function
Goal of RL (Finite Horizon / Episodic)
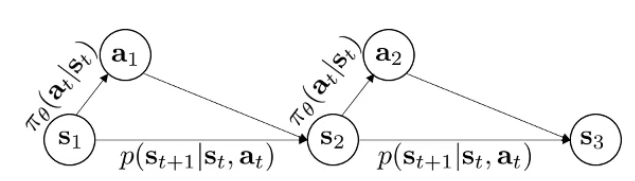
Pθ(τ),where τ represents sequence of trajectorypθ(s1,a1,…,sT,aT)=P(s1)t=1∏TMarkov chain on (s,a)πθ(at∣st)P(st+1∣st,at)
So our goal is to maximize the expectation of rewards
θ∗=θargmaxEτ∼pθ[t∑r(st,at)]
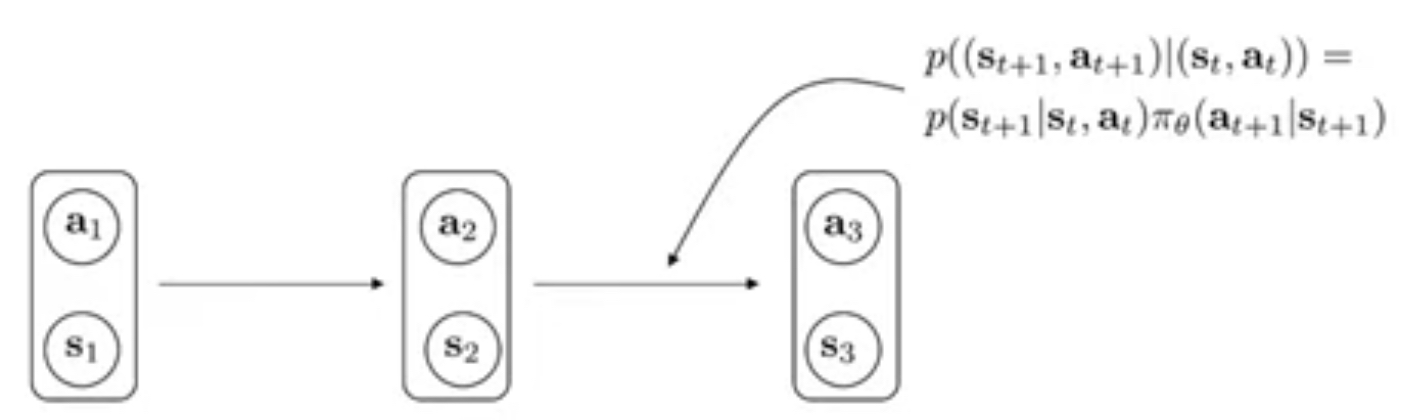
Group action and state together to form augmented statesAugmented states form a Markov Chain.
Use average award θ∗=argmaxθT1Eτ∼pθ(τ)[∑tr(st,at)]
Use discounts
Q: Does p(st,at) converge to a stationary distribution as t→∞?
Ergodic Property: Every state can transition into another state with a non-zero probability.
“Stationary”: The same before and after transition
stationary means the state is same and before after transitionμ=Tμ
(T−I)μ=0
This means that μ is an eigenvector of T with eigenvalue of 1 (always exists under some regularity conditions)
μ=pθ(s,a)→stationary distribution
As t goes further and further from infinity, the reward terms starts to get dominated by the stationary distribution (we have almost inifite μ states and a finite non-stationary action/state pairs
RL is about maximizing the expectation of rewards. And expectations can be continuous in the parameters of the corresponding distributions even when the function we are taking expectation of is itself highly discontinuous. Because of this property we can use smooth optimization methods like Gradient Descent
📌
Because the distribution of the probability of getting a reward usually has a continuous PDF.
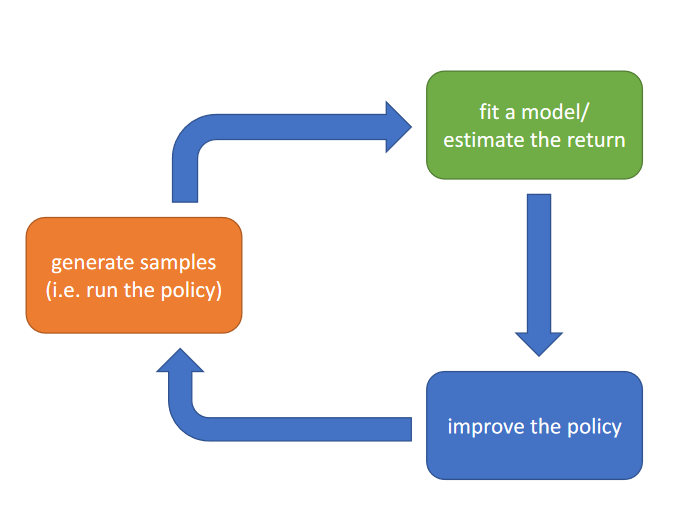
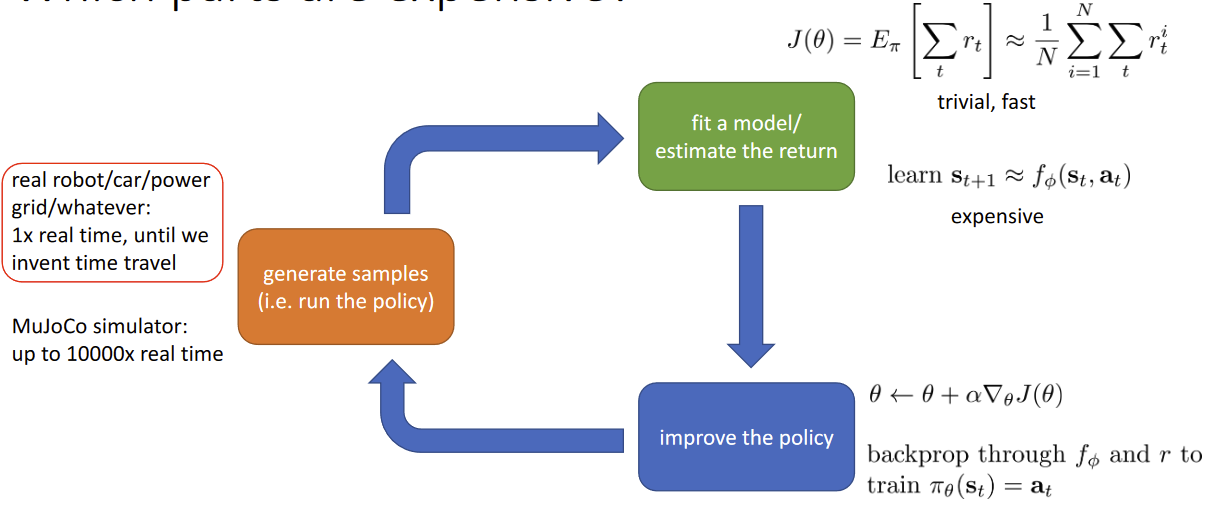
High-level anatomy of reinforcement learning algorithms
Which parts are expensive?
Value Function & Q Function
Remember that RL problems are framed as argmax of expectation of rewards, but how do we actually deal with the expectations?
📌
Write it out recursively!
We can write this expectation out explicitly as a nested expectation (looks like a DP algorithm!)
Looks like its messy, but what if we have a function that tells us what value inside the Ea1∼π(a1∣s1) is?
Specifically, its the value of
r(s1,a1)+Es2∼p(s2∣s1,a1)[Ea2∼π(a2∣s2)[r(s2,a2)+⋯∣s2]∣s1,a1]
We will define it as our Q function
It’s a lot easier to modify the parameter θ of πθ(a1∣s1) if Q(s1,a1) is known
Q-Function Definition
Qπ(st,at)=t′=t∑TEπθ[r(st′,at′)∣st,at]→total reward from taking at in st
Value Function Definition
Vπ(st)=t′=t∑TEπθ[r(st′,at′)∣st]→total reward from st
Vπ(st)=Eat∼π(at∣st)[Qπ(st,at)]
Now Es1∼p(s1)[Vπ(s1)] is the RL objective.
To use those two functions:
If we have policy π, and we know Qπ(s,a), then we can improve π:
set π′(a∣s)=1 if a=aargmaxQπ(s,a)
(This policy is at least as good as π and probably better)
OR
Compute gradient to increase the probability of good actions a
if Qπ(s,a)>Vπ(s), then a is better than average. Recall that Vπ(s)=E[Qπ(s,a)] under π(a∣s).
Modify π(a∣s) to increase the probability of a if Qπ(s,a)>Vπ(s)