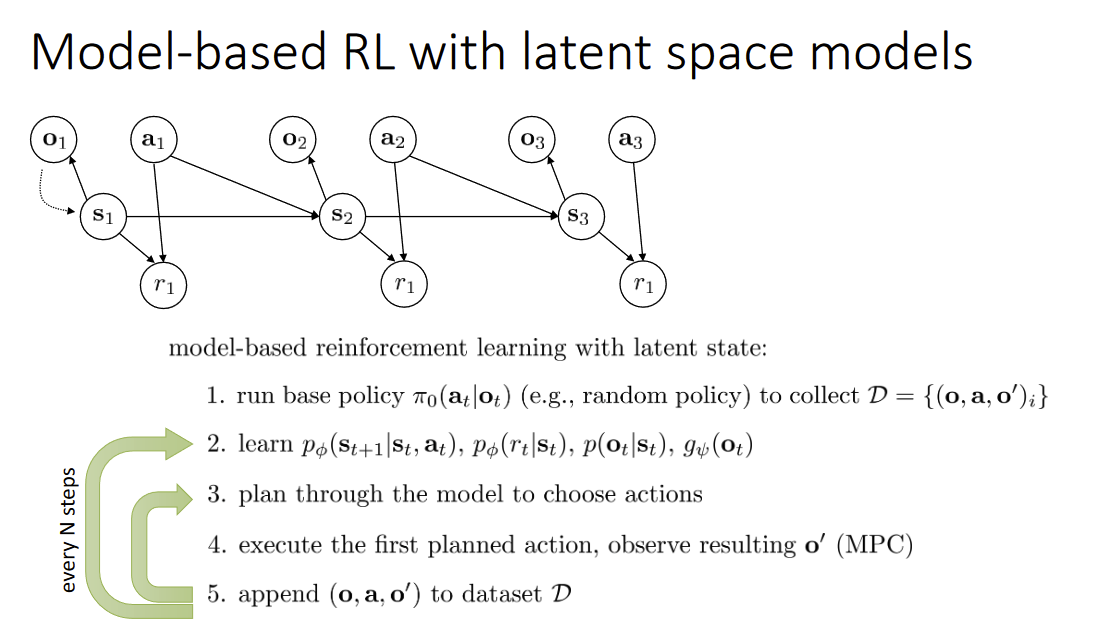
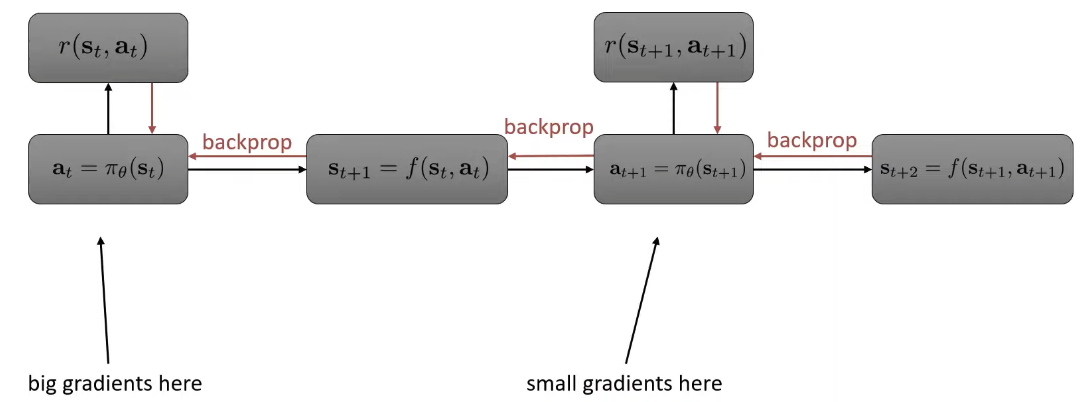
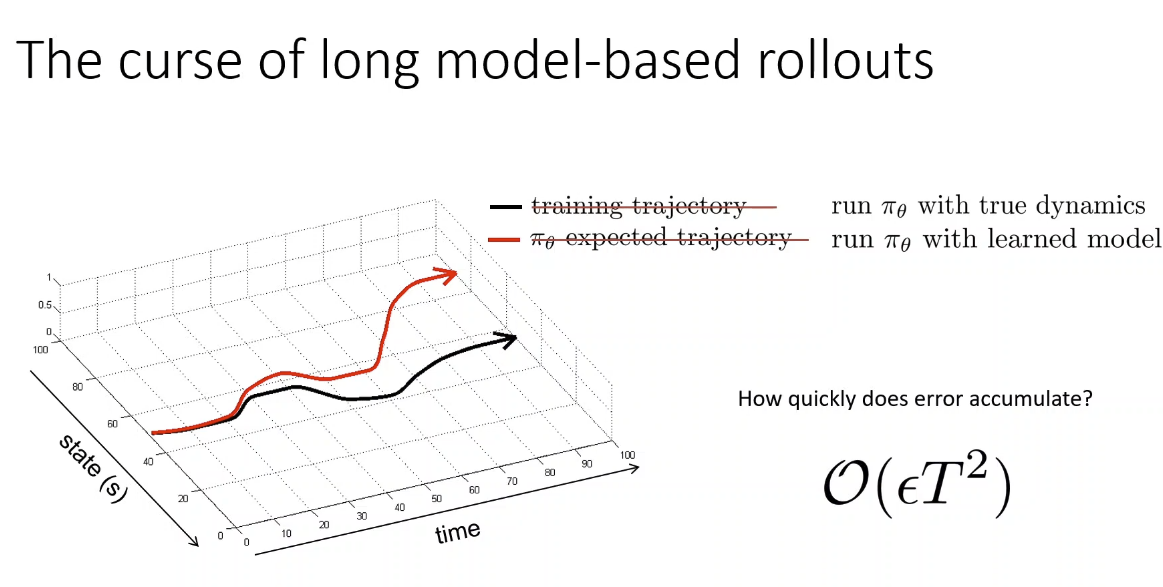
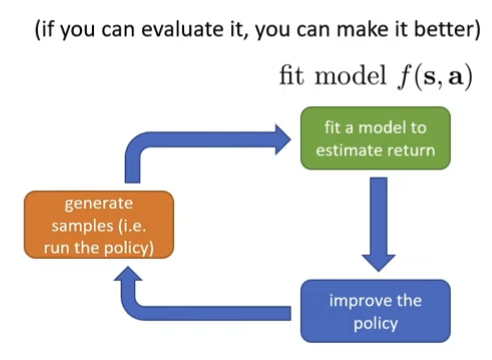
Why Model-based methods? Because if we know the transition function f(st,at)=P(st+1∣st,at) then we can use trajectory planning ⇒ So we can learn f(st,at) from data
📌
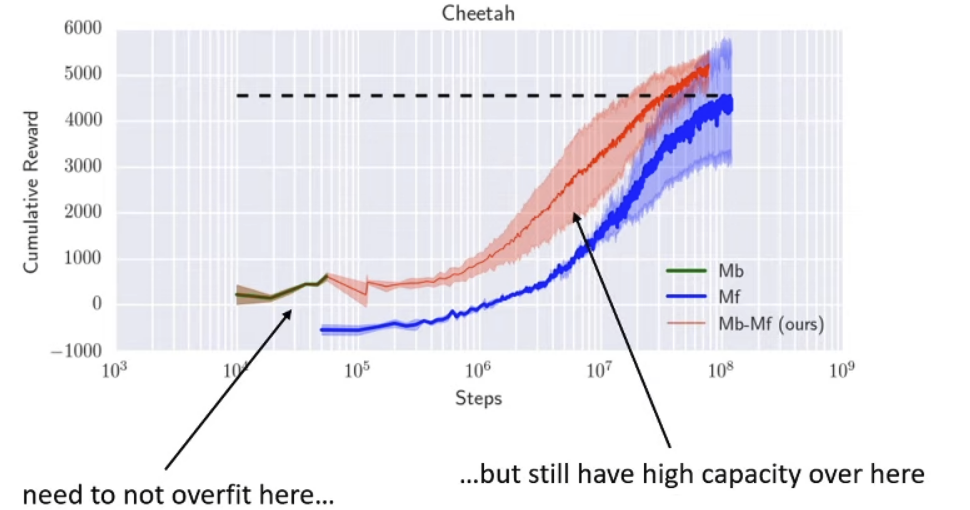
Model-based RL can be prone to error in distribution mismatch ⇒ very like behavior cloning because when planned trajectory queries out-of-sample states, then f(⋅) is likely to be wrong
NPC
Performance Gap Issue
We want good exploration to gather more data to address the distribution shift, but with a not-so-good early model we cannot deploy good exploration techniques
Basically the model early on overfits an function approximator and the exploration policy is stuck on a local minima / maxima
Uncertainty Estimation
Uncertainty estimation helps us reduce performance gap.
Under this trick, the expectation of reward under high-variance prediction is very low, even though the mean is the same
However:
We still need exploration to get better model
Expected value is not the same as pessimistic value
But how to build it?
Use NN?
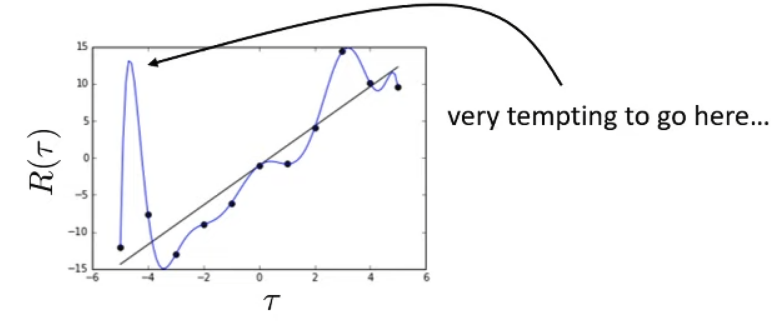
Cannot express uncertainty of unseen data accurately ⇒ when querying out-of-sample data, the uncertainty output is arbitrary
“The model is certain about data, but we are not certain about the model”
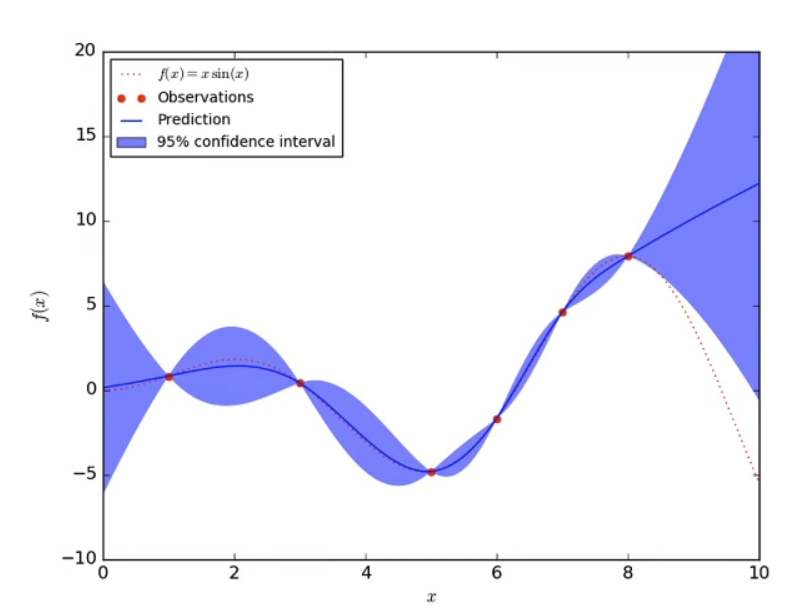
Estimate Model Uncertainty
Estimate argmaxθlogP(θ∣D)=argmaxθlogP(D∣θ)
Can we instead estimate the distribution P(θ∣D)?
We can use this to get a posterior distribution over the next state
∫p(st+1∣st,at,θ)p(θ∣D)dθ
Bayesian Neural Nets
Every weight, instead of being a number, is a distribution
But it’s difficult to join parameters into a single distribution
So we do approximation
p(θ∣D)=∏ip(θi∣D)
Very Crude approximation
p(θi∣D)=N(μi,σi2)
Instead of learning numerical value learn mean value and std/variance
Bllundell et al. Weight Uncertainty in Neural Networks
Gal et al. Concrete Dropout
Bootstrap Ensembles
Train several different neural nets and bootstrap samples(Di sample with replacement from D) to feed to those networks
So each network learns slightly differently
In theory each NN learns well on their own training data but makes different mistakes outside of training data
Policy gradient might be more stable (if enough samples are used) because it does not require multiplying many Jacobians
Parmass et al. “18: PIPP: Flexible Model-Based Policy Search Robust to the Curse of Chaos”
It we use policy gradient to backprop through our model dynamics model, there would still be a problem (although generating samples does not require interacting with physical world or simulator)
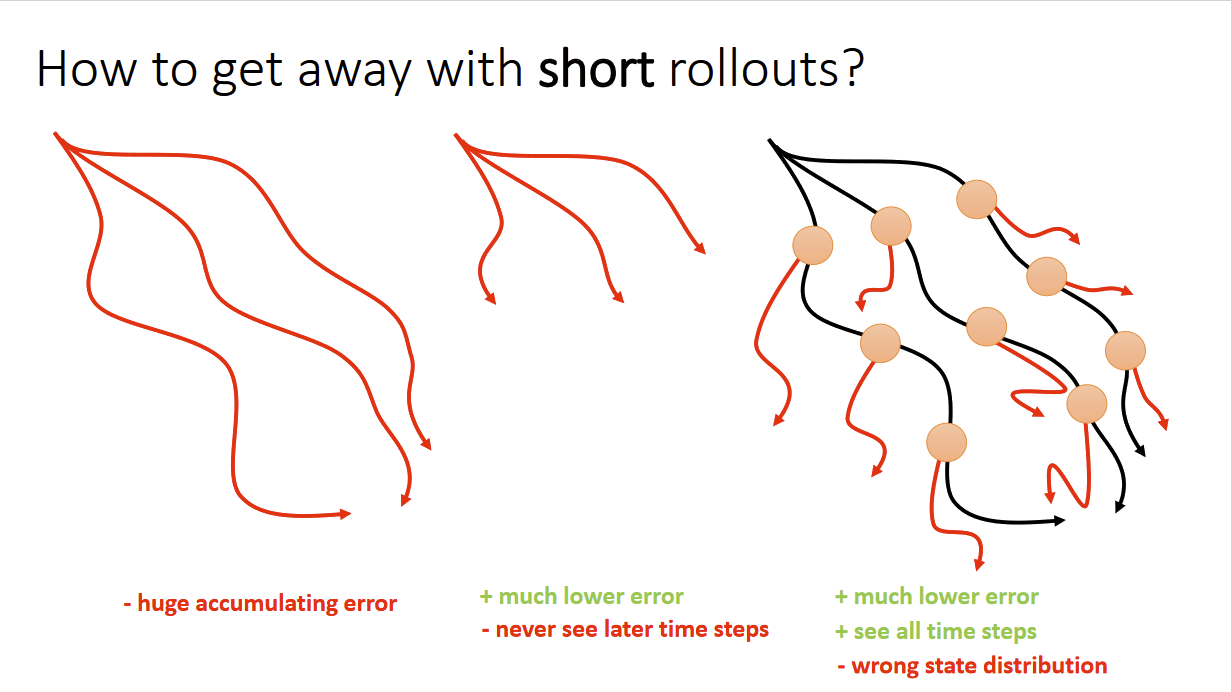
Left: Open-loop planning with long rollouts; Middle: Open-loop planning with shorter rollouts; Right: Collect real-world data from current policy and do short rollouts planning with data sampled from real distribution
But this does not solve the problem because the point of using model-based RL is being sample efficient and using sampled real world data and do short-rollout open-loop planning restrict how much we can change our policy.
Model-based RL with Policies
📌
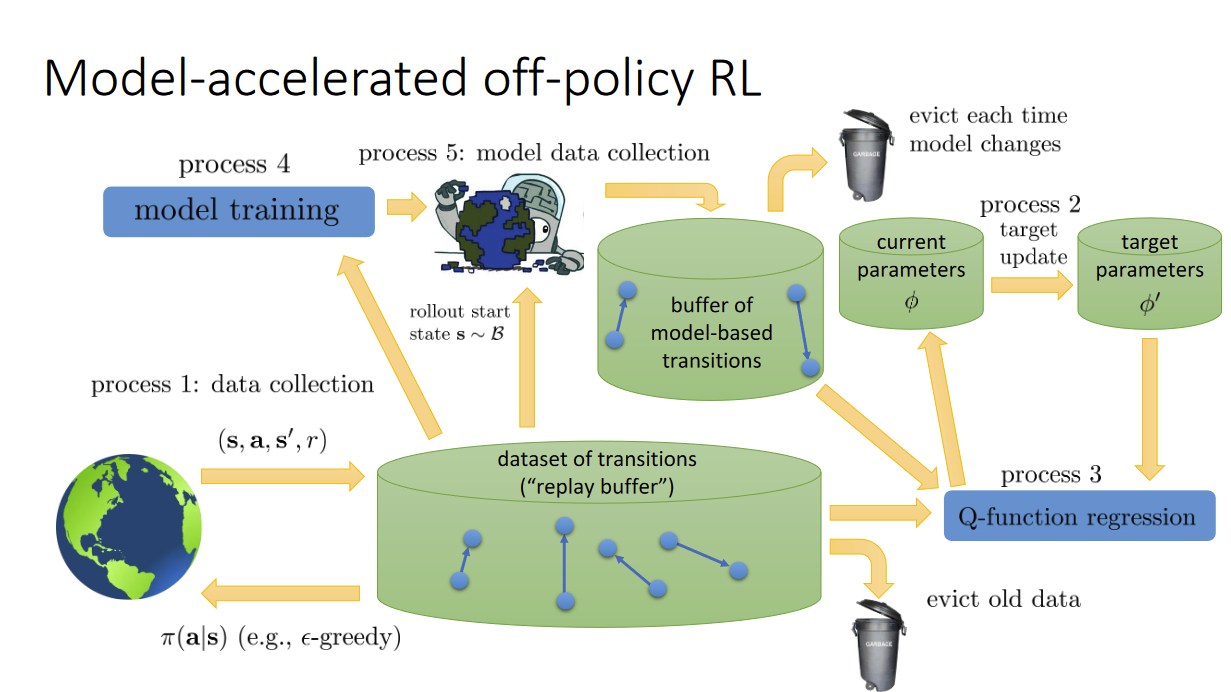
Question is how to use the model’s predictions? fit Q functions or Value functions or what?
Model-Based Acceleration (MBA)
Gu et al. Continuous deep Q-learning with model-based acceleration. ‘16
Model-Based Value Expansion (MVE)
Feinberg et al. Model-based value expansion. ’18
Model-Based Policy Optimization (MBPO)
Janner et al. When to trust your model: model-based policy optimization. ‘19
Good Idea:
Sample Efficient
Bad Idea:
Additional Source of bias if model is not correct
Reduce this by using ensemble methods
If not seen states before then we still cannot perform valid action
Multi-step Models and Successor Representations
📌
The job of the model is to evaluate the policy
Vπ(st)=t=t′∑∞γt′−tEp(st′∣stEat′∣st′)[r(st′,at′)]=t=t′∑∞γt′−tEp(st′∣st)[r(st′)]=t=t′∑∞γt′−ts∑p(st′=s∣st)r(s)=s∑Add (1−γ) term to the front makes it pπ(sfuture=s∣st)(t=t′∑∞γt′−tp(st′=s∣st))r(s)