Transfer Learning & Meta-RL
Transfer Learning
Transfer Learning: Use experience from one set of tasks for faster learning and better performance on a new task!
How is the knowledge stored:
- Q-Function: Tells us which actions or states are good
- Policy: Tells us which actions are potentially useful
- Some actions are never useful!
- Models:
- What are laws of physics that govern the world?
- Features/hidden states:
- Provides us with a good representation
Several types of transfer learning problems:
- Forward transfer
- Learn policies that transfer effectively
- Train on source task, then run on target task (finetune)
- Multi-task transfer
- Train on many tasks, transfer to a new task
- Sharing representations and layers across tasks in multi-task learning
- New tasks need to be similar to the distribution of training tasks
- Meta-learning
- Learn to learn on many tasks
- Accounts for the fact that we will be adapting to a new task during training
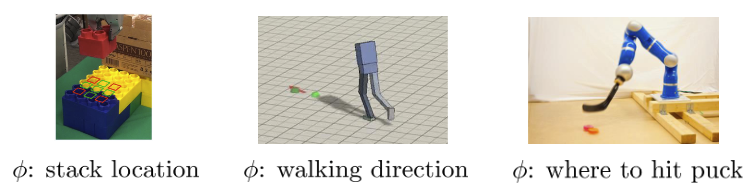
Invariance Assumption: Everything that is different between domains is irrelevant
Formally: is different; exists some such that but is same
- Distribution is different, but featurization is the same
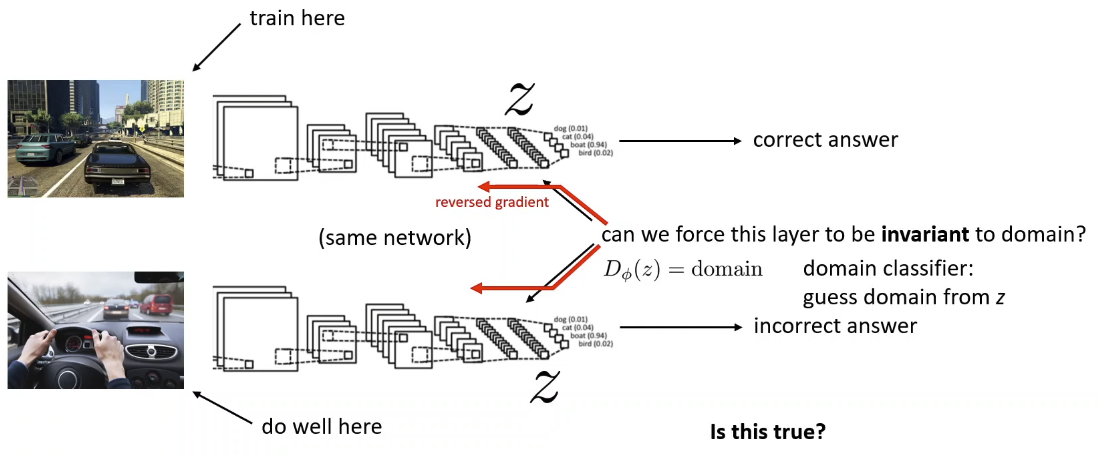
- Invariance is not enough when the dynamics don’t match
Challenges of fine-tuning
- RL Tasks are generally much less diverse
- Features are less general
- Policies and value functions become overly specialized
- Optimal policies in fully observed MDPs are deterministic
- Loss of exploration at convergence
- Low-entropy policies adapt very slowly to new settings
- “Randomization” (dynamics/appearance/etc.) widely used for simulation to real world transfer
Suggested Readings
- Domain Adaptation
- Tzeng, Hoffman, Zhang, Saenko, Darrell. Deep Domain Confusion: Maximizing for Domain Invariance. 2014.
- Ganin, Ustinova, Ajakan, Germain, Larochelle, Laviolette, Marchand, Lempitsky. Domain-Adversarial Training of Neural Networks. 2015.
- Tzeng*, Devin*, et al., Adapting Visuomotor Representations with Weak Pairwise Constraints. 2016.
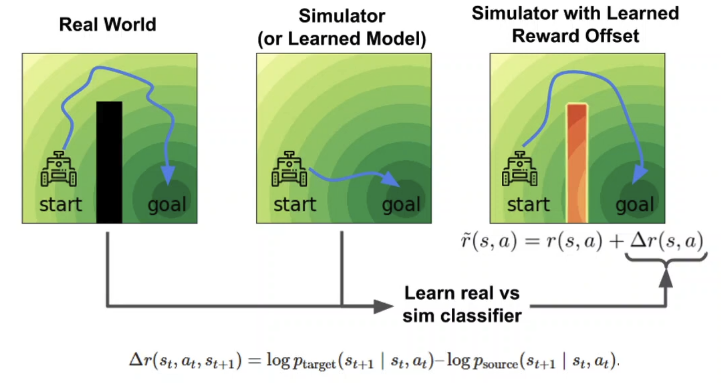
- Eysenbach et al., Off-Dynamics Reinforcement Learning: Training for Transfer with Domain Classifiers. 2020.
- Finetuning:
- Finetuning via MaxEnt RL: Haarnoja*, Tang*, et al. (2017). Reinforcement Learning with Deep Energy-Based Policies.
- Andreas et al. Modular multitask reinforcement learning with policy sketches. 2017.
- Florensa et al. Stochastic neural networks for hierarchical reinforcement learning. 2017.
- Kumar et al. One Solution is Not All You Need: Few-Shot Extrapolation via Structured MaxEnt RL. 2020
- Simulation to real world transfer:
- Rajeswaran, et al. (2017). EPOpt: Learning Robust Neural Network Policies Using Model Ensembles.
- Yu et al. (2017). Preparing for the Unknown: Learning a Universal Policy with Online System Identification.
- Sadeghi & Levine. (2017). CAD2RL: Real Single Image Flight without a Single Real Image.
- Tobin et al. (2017). Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World.
- Tan et al. (2018). Sim-to-Real: Learning Agile Locomotion for Quadruped Robots
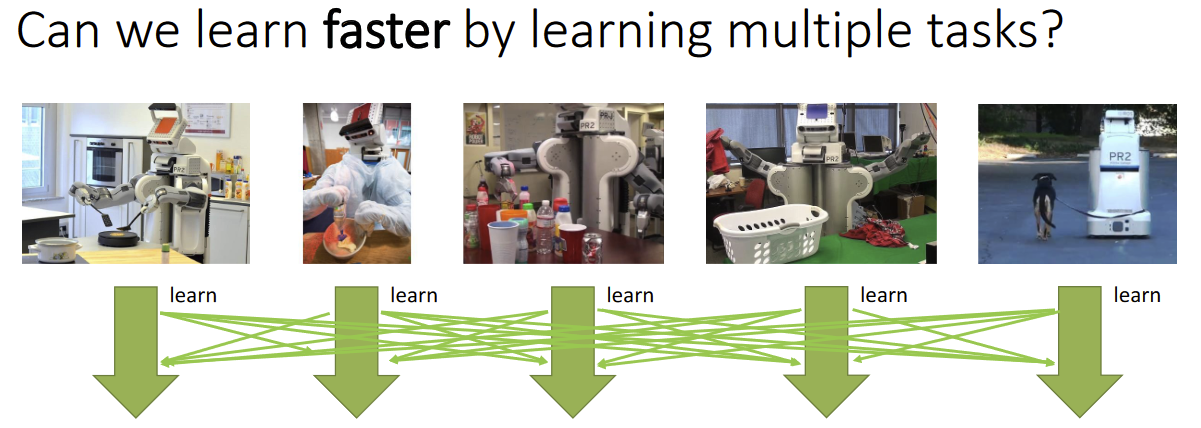
Multi-task learning can
- Accelerate learning of all tasks that are learned together
- Provide better pre-training for down-stream tasks
- Corresponds to single-task RL in a joint MDP
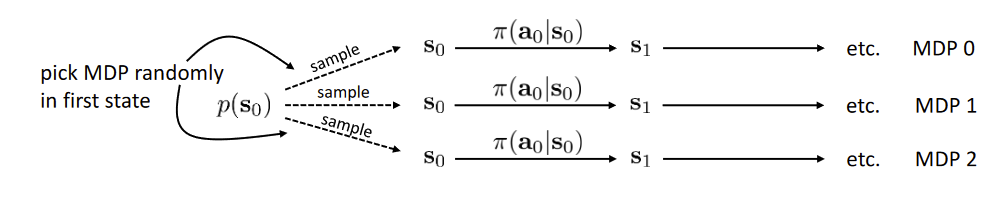
Or we can add a “what to do” variable (usually a one-hot variable) for the policy for it to know what to do
This is a contextual policy
A particular choice is a “goal-conditioned” policy where the “what-to-do” variable is another state ⇒
-
- No need to manually define rewards for each task
- Transfer in zero shot to a new task if it’s another goal
- Hard to train in practice
Relevant Papers (Goal-Conditioned Policy)
- Kaelbling. Learning to achieve goals.
- Schaul et al. Universal value function approximators.
- Andrychowicz et al. Hindsight experience replay.
- Eysenbach et al. C-learning: Learning to achieve goals via recursive classification
Meta-learning
- If learned 100 tasks already, figure out how to learn more efficiently
- Having multiple tasks is a huge advantage now
- Meta-learning = learning to learn
- In practice is very related to multitask learning
- Common formulations
- Learning an optimizer
- Learning an RNN that ingests experience
- Learning a representation
Vision:
- Deep reinforcement learning, especially model-free, requires a huge number of samples
- If we can meta-learn a faster RL learner, we can learn new tasks efficiently
- A meta-learned leaner (maybe) can
- Explore more intelligently
- Avoid trying actions that are know to be useless
Three Perspectives
- RNN
- Conceptually simple
- relatively easy to apply
- vulnerable to meta-overfitting
- challenging to optimize in practice
- Gradient-based approach
- Good extrapolation (’consistent”)
- Conceptually elegant
- Complex, requires many samples
- Inference problem (VAE)
- Simple, effective exploration via posterior sampling
- Elegant reduction to solving a special POMDP
- vulnerable to meta-overfitting
- challenging to optimize in practice
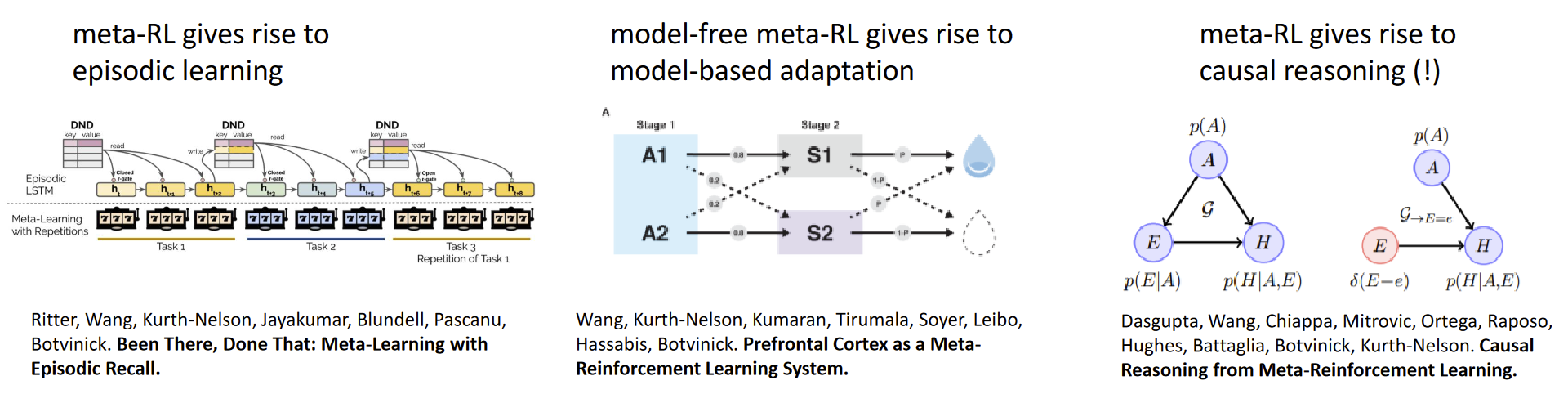
Meta RL and emergent phenomena
Humans and animals seemingly learn behaviors in a variety of ways
- Highly efficient but model-free RL
- Episodic recall
- Model-based RL
- Causal Inference
Perhaps each of these is a separate “algorithm” in the brain
But maybe these are all emergent phenomena resulting from meta-RL?
Meta-learning with supervised learning
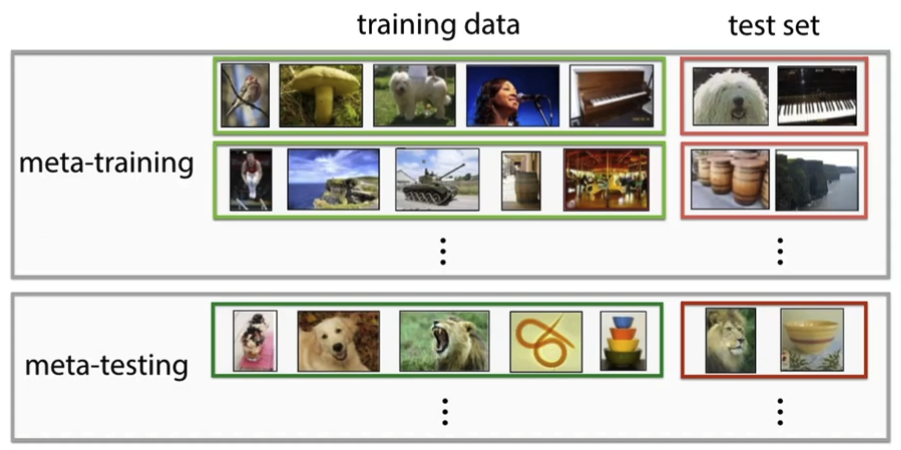
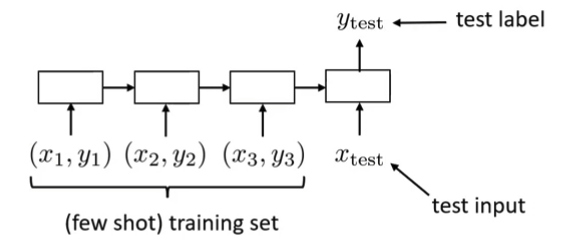
Supervised learning:
- ⇒ input (image)
- ⇒ output (label)
- Learn
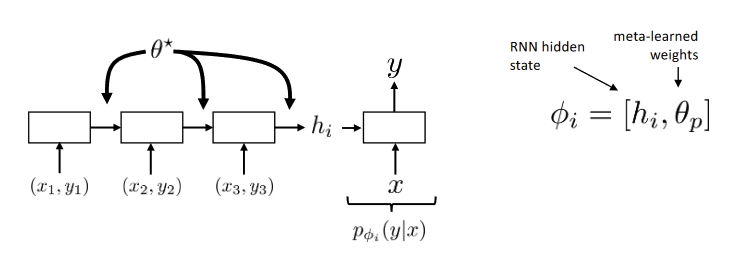
Supervised meta-learning:
- ⇒ training set
- To read in, use RNN (GRU/LSTM/Transformers)
- Learn
- Where
- weight trained with training set
Meta-learning in RL

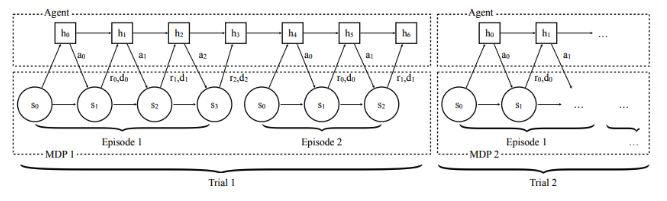
Contextual Policies and Meta-Reinforcement Learning are closely related:

- In multi-task RL, the task(context) is typically given
- In meta-RL, the context is inferred from experience from
Meta-RL with recurrent policies:
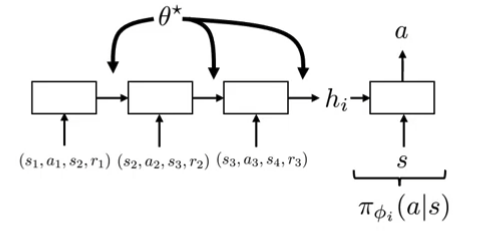
What should do?
- Improve policy with experience from
-
- Choose how to interact (choose )
- How to explore
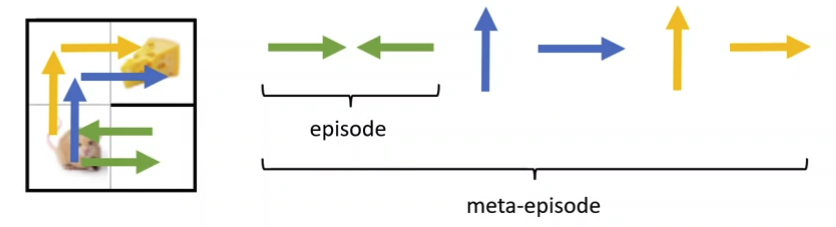
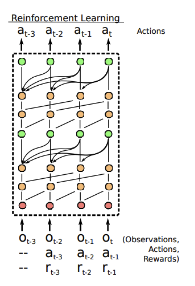
This Recurrent Policies will learn to explore
- RNN hidden state is not reset between episodes!
- Optimizing total reward over the entire meta-episode with RNN policy automatically learns to explore!
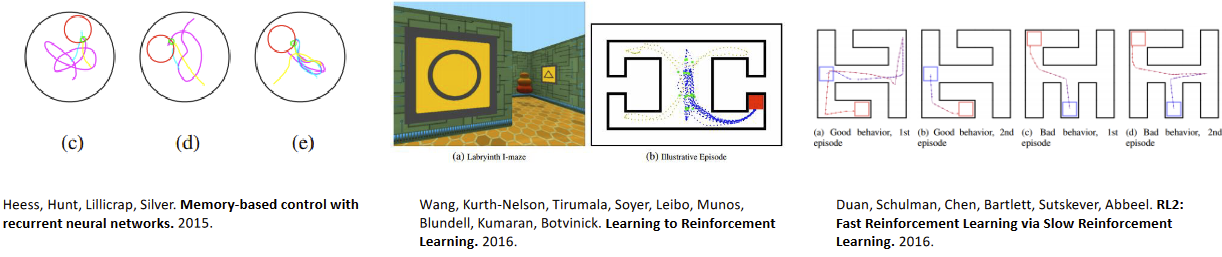
Architetures for Meta-RL
Gradient-based Meta-RL
Finn, Abbeel, Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. (MAML)
- Is pretraining a type of meta-learning?
- Better feature representations = faster learning of a new task!
For meta-learning, the formulation is:
What if is itself an RL algorithm?
Note: Gradient terms requires interacting with to estimate
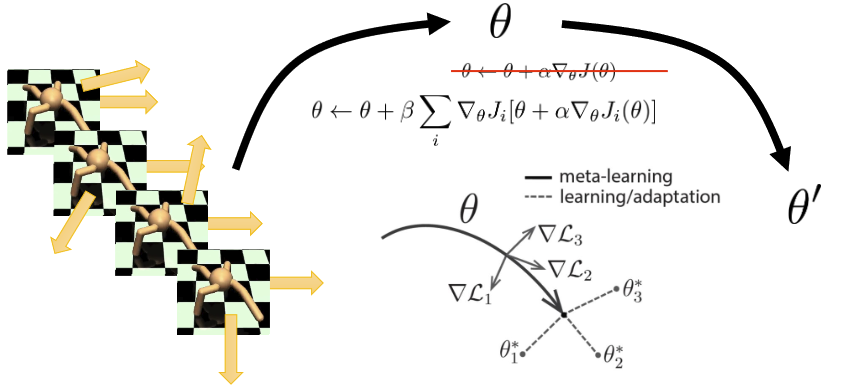
- Has favorale inductive bias
Suggestive Readings
- MAML meta-policy gradient estimators:
- Finn, Abbeel, Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
- Foerster, Farquhar, Al-Shedivat, Rocktaschel, Xing, Whiteson. DiCE: The Infinitely
- Differentiable Monte Carlo Estimator.
- Rothfuss, Lee, Clavera, Asfour, Abbeel. ProMP: Proximal Meta-Policy Search.
- Improving exploration:
- Gupta, Mendonca, Liu, Abbeel, Levine. Meta-Reinforcement Learning of Structured
- Exploration Strategies.
- Stadie*, Yang*, Houthooft, Chen, Duan, Wu, Abbeel, Sutskever. Some Considerations on Learning to Explore via Meta-Reinforcement Learning.
- Hybrid algorithms (not necessarily gradient-based):
- Houthooft, Chen, Isola, Stadie, Wolski, Ho, Abbeel. Evolved Policy Gradients.
- Fernando, Sygnowski, Osindero, Wang, Schaul, Teplyashin, Sprechmann, Pirtzel, Rusu. Meta-Learning by the Baldwin Effect.
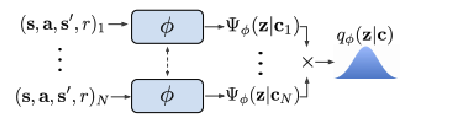
Meta RL as POMDP (Variational Inference)
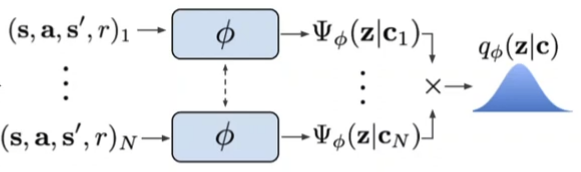
Rakelly, Zhou, Quillen, Finn, Levine, Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables, ICML 2019.
Policy:
Inference network:

- Stochastic enables exploration via posterior sampling
Suggested Reading
- Rakelly*, Zhou*, Quillen, Finn, Levine. Efficient Off-Policy Meta-Reinforcement learning via Probabilistic Context Variables. ICML 2019.
- Zintgraf, Igl, Shiarlis, Mahajan, Hofmann, Whiteson. Variational Task Embeddings for Fast Adaptation in Deep Reinforcement Learning.
- Humplik, Galashov, Hasenclever, Ortega, Teh, Heess. Meta reinforcement learning as task inference.