GAN3: Apply GANs
Some notes of GAN(Generative Adversarial Network) Specialization Course by Yunhao Cao(Github@ToiletCommander)
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Acknowledgements: Some of the resources(images, animations) are taken from:
- Sharon Zhou & Andrew Ng and DeepLearning.AI’s GAN Specialization Course Track
- articles on towardsdatascience.com
- images from google image search(from other online sources)
Since this article is not for commercial use, please let me know if you would like your resource taken off from here by creating an issue on my github repository.
Last updated: 2022/6/16 14:15 CST
Applying GANS
Gans can be used to
- Image-to-image translation
- Data augmentation
- supplement data when real data is too expensive or rare
- traditionally done by cropping, rotating, flipping images, etc.
- now we can use generators
- RandAugment paper to tell how to augment based on scenerio
- GAN has been shown to be better than synthetic data, plus it can be used to generate labeled examples
- Encourages data-sharing, less expensive, and protects real data
- looks real to professionals(pathogen doctor) eyes who look at samples every day
- but GAN’s diversity is always limited by the data available
- so GANS can generate samples that are too close to the reals
Image-to-image translation
- Black-white image to colored?
- Segmentation Map to photorealistic images
- Paired image-to-image translation
- Image to image
- Other Translations
- Text to image?
Unpaired image-to-image translation
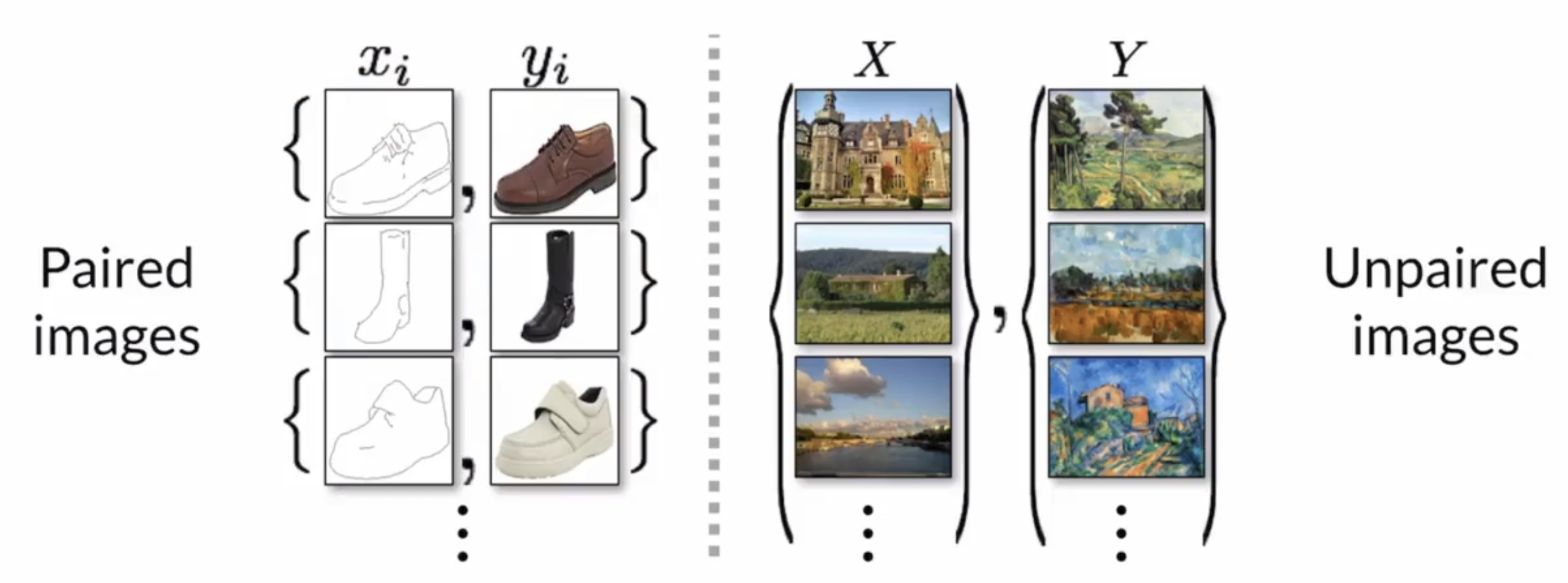
With paired image-to-image translation, you get a one-to-one correspondence between the input and the output while in unpaired image-to-image translation the input and the output are generally two different piles of image that have different styles
So in an unpaired image translation task, you want to
- Still learn a mapping between the two piles
- Examine the common elements of the two piles (content) and unique elements of each pile (style)
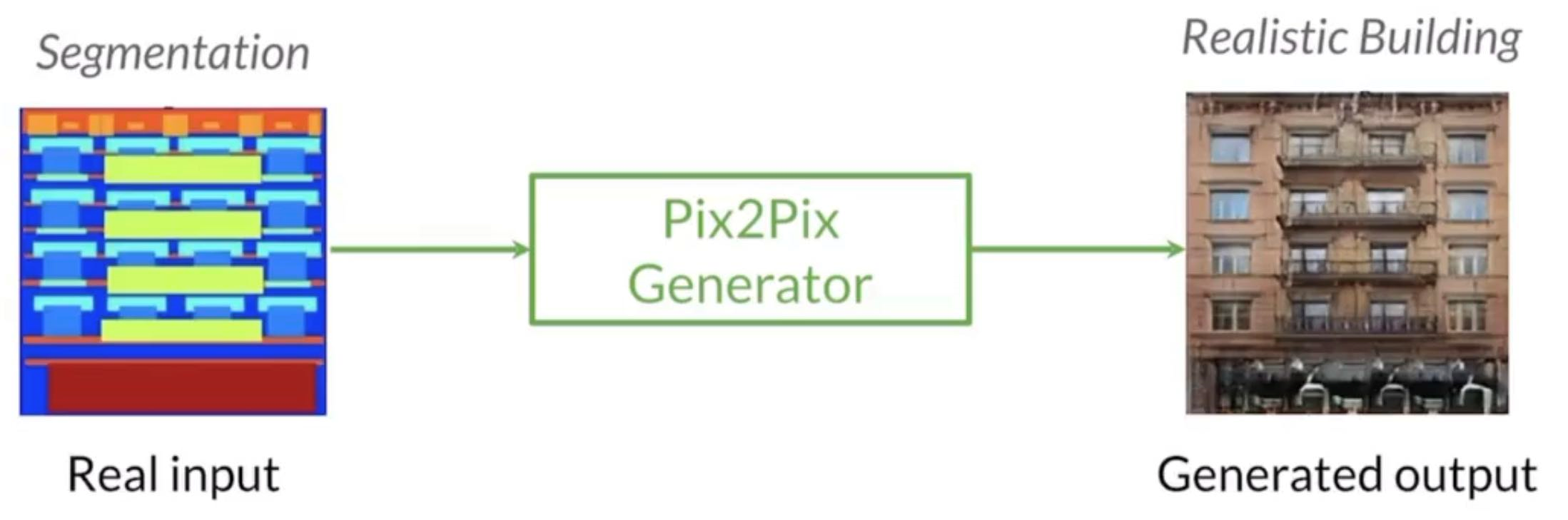
Pix2Pix
Paired Image-to-Image Translation Model from UC Berkeley, Yeah!!!!
Instead of inputting a noise vector, we would input a real input (segmentation map, etc.) and it would translate into another paired output. Noise vector is not introduced but we would use dropout to add randomness to the output.
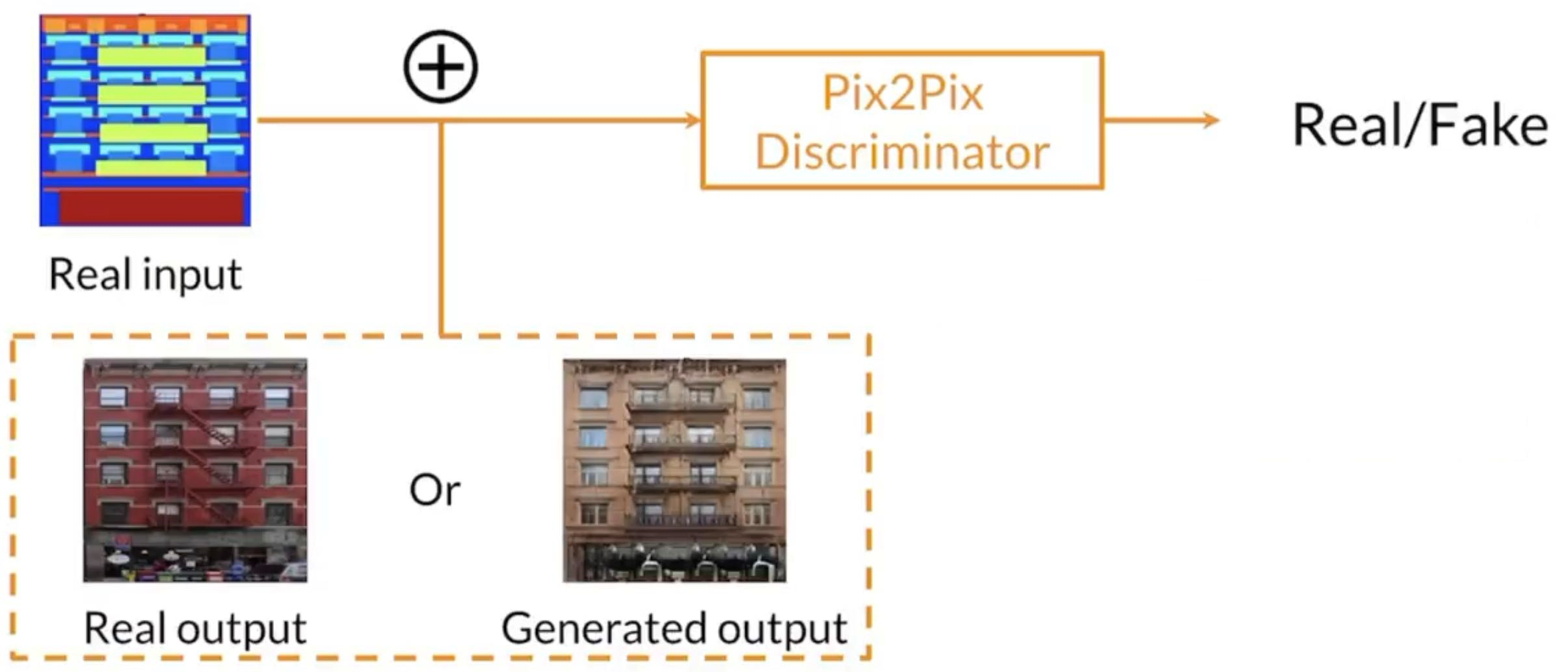
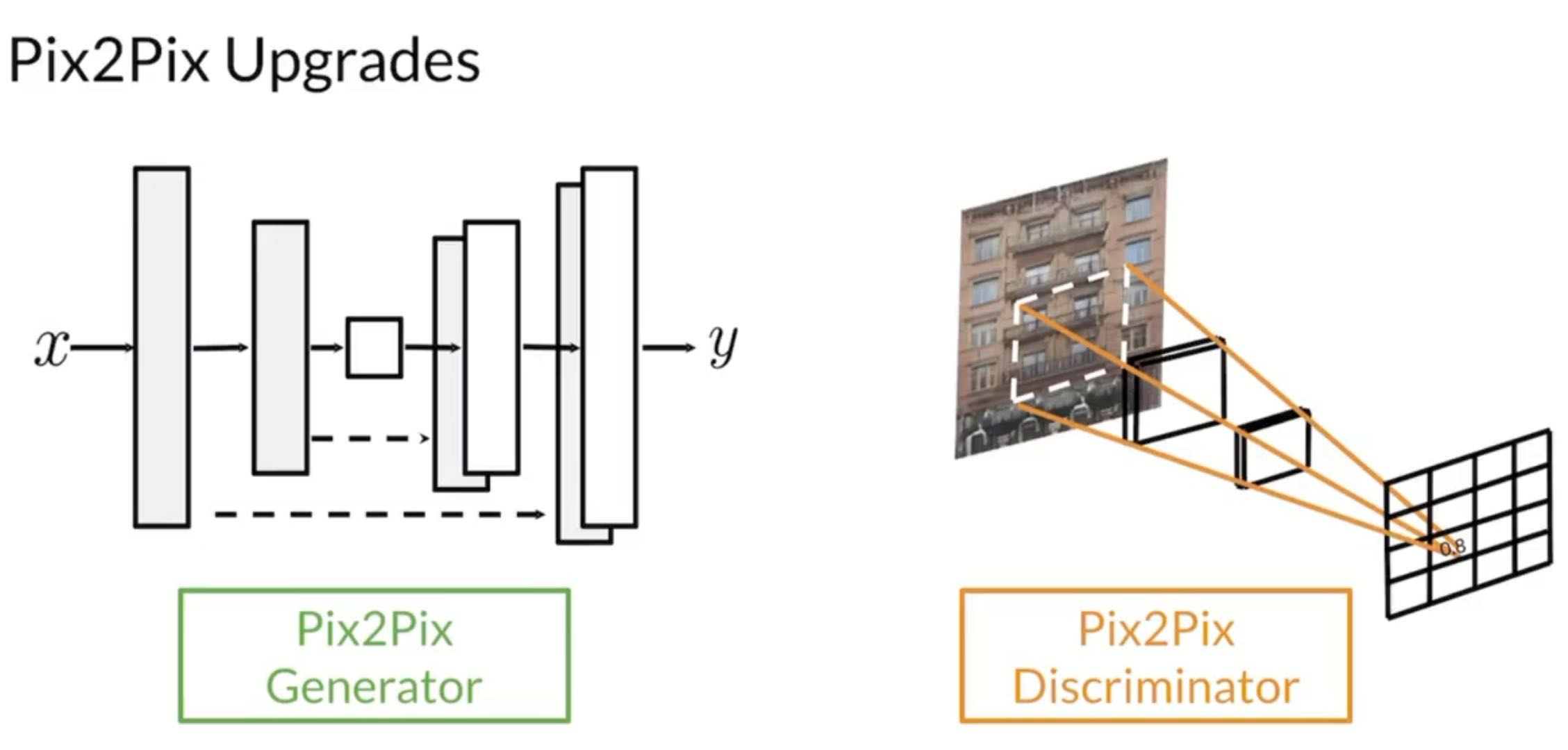
Pix2Pix Discriminator - PatchGAN
- Outputs a matrix of evaluations instead of just one value, the values of each element in the matrix is between 0 to 1.
- gives feedback to specific “path”
- value closer to 0 ⇒ fake
- value closer to 1 ⇒ real
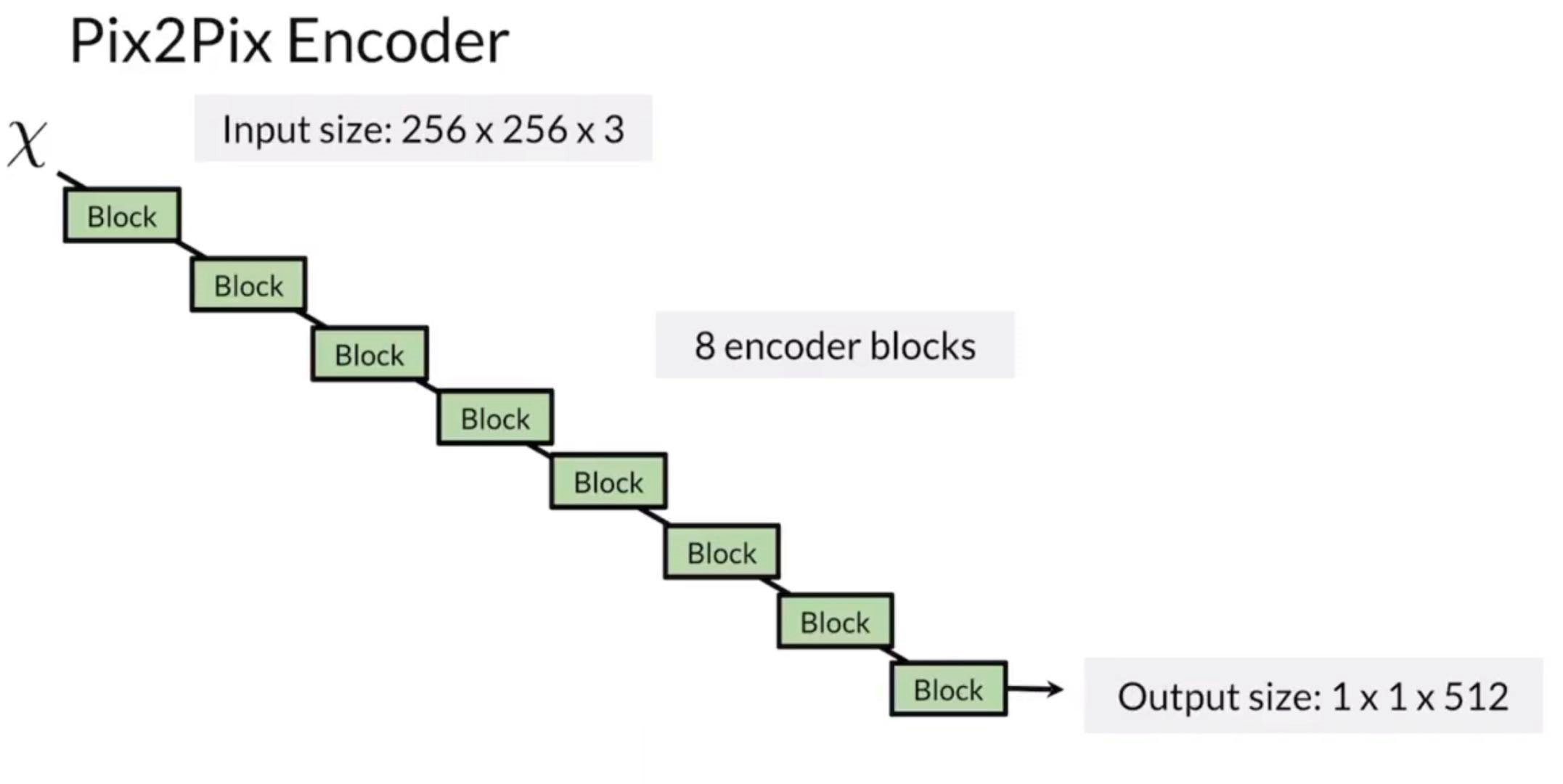
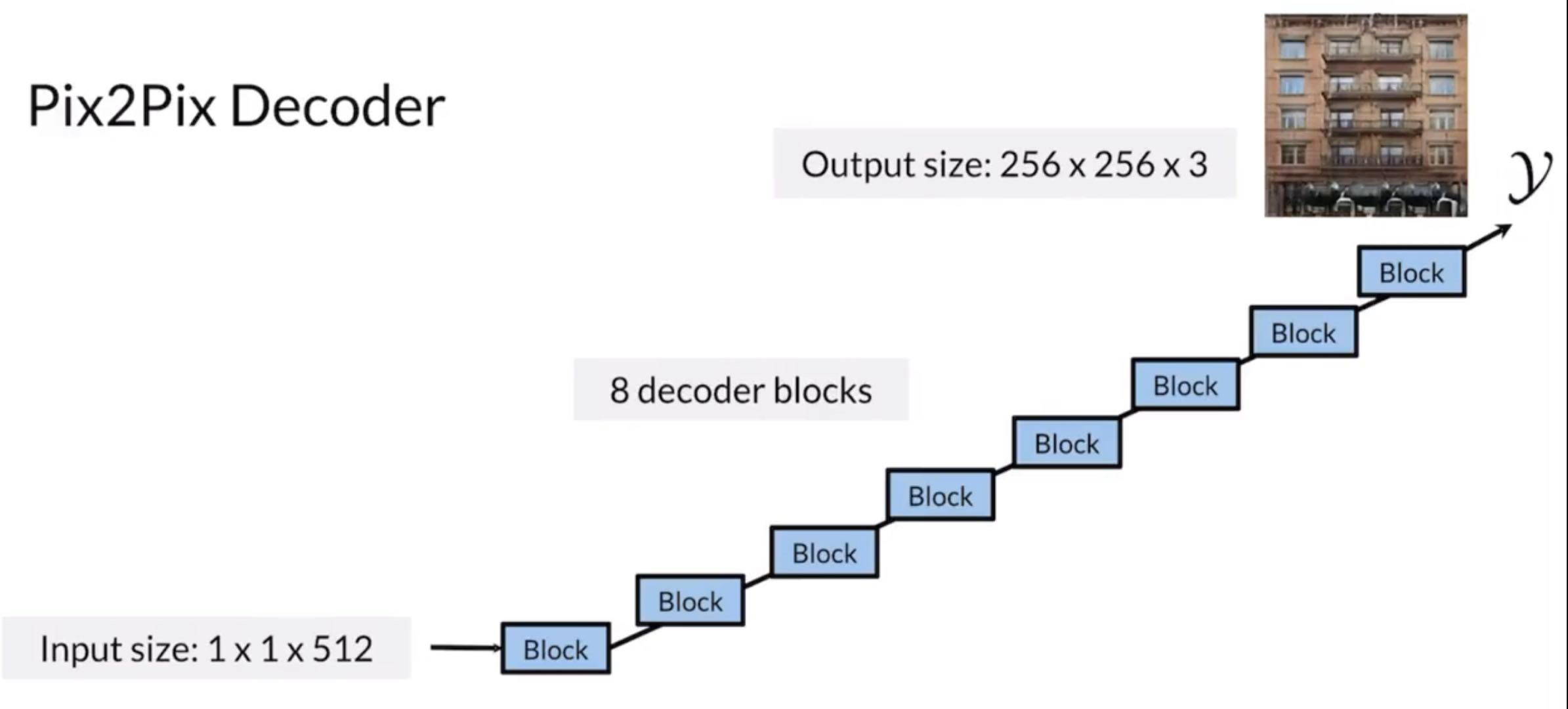
Pix2Pix Generator - UNet
UNet has been very successful for image segmentation
See my notes on DL Specialization course 4
But for segmentation and generation, they are different
- There is not a correct answer for generation
- for a car area, we can generate a car, a truck, a bus, etc.
- Since we picked up an image instead of a noise vector, the generator has to be beefier.
- skip connections to help vanishing gradient problem, and bottlenet helps to embed information
Dropout is added to some decoder blocks(first 3 blocks) ⇒ adds noise to the network
At inference time, dropout is actually disactivated and scaling is used to maintain the stability of distribution
PixelDistance Loss Term
An additional loss term for pix2pix model
Objective
So loss function for pix2pix model
The Pixel Loss is equal to...
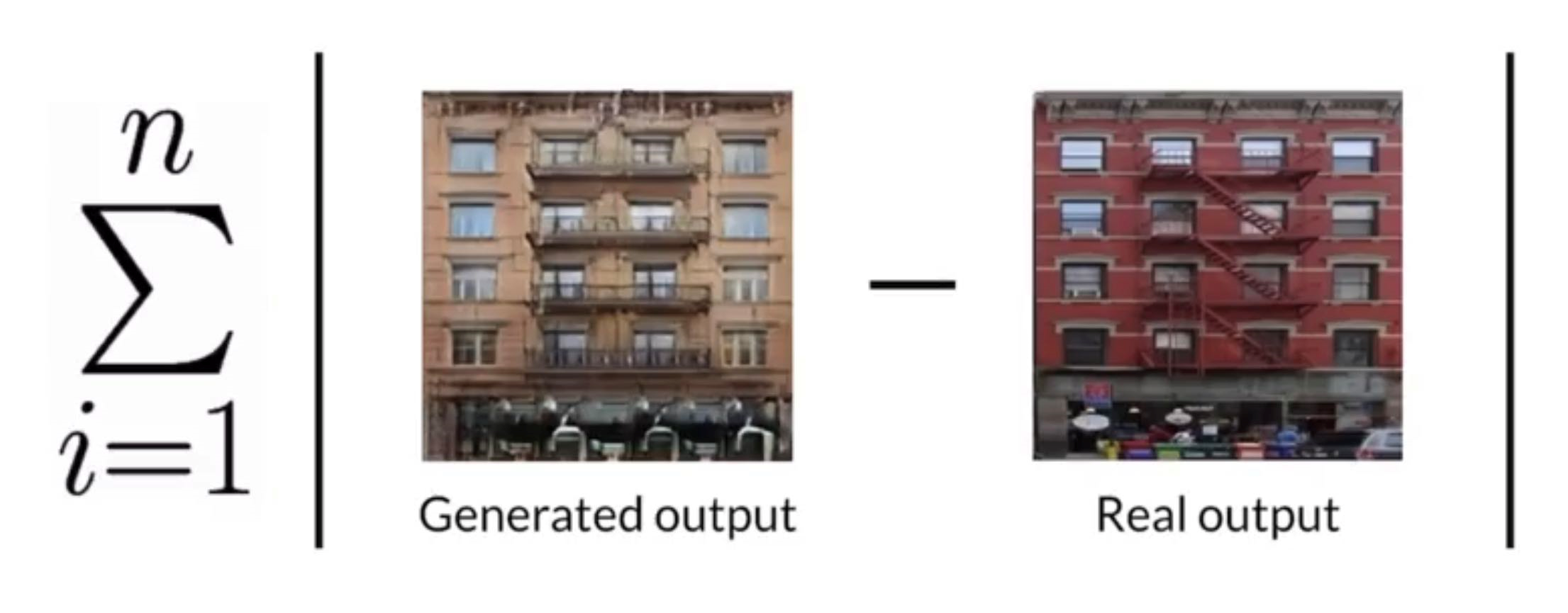
Comes handy for getting exactly close to what is real
Added layer of supervision also...which is kind of bad (but very soft, since its only abs not squared distance)
Successors: Pix2PixHD, GauGAN
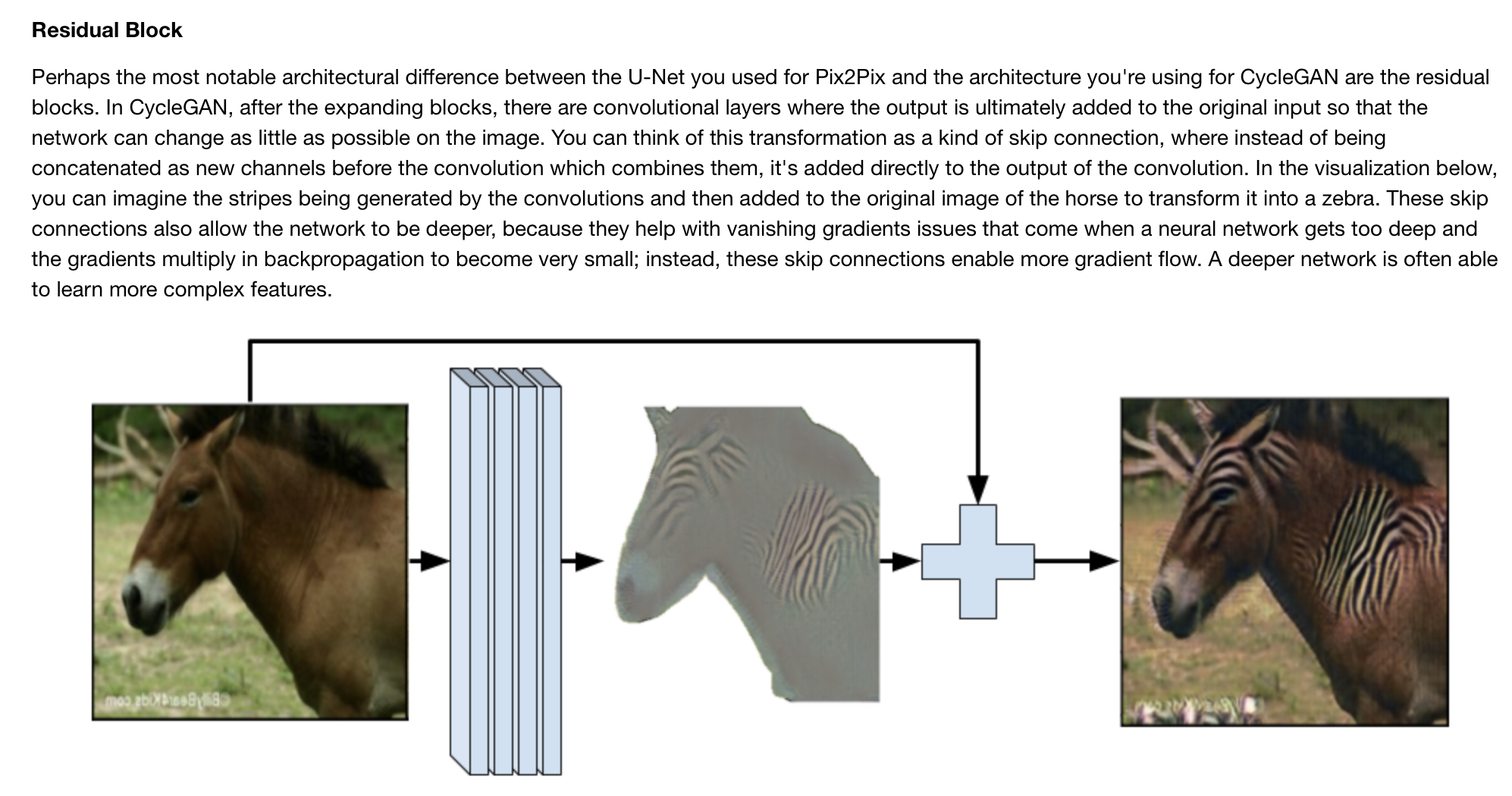
CycleGAN
Unpaired image-to-image translation model

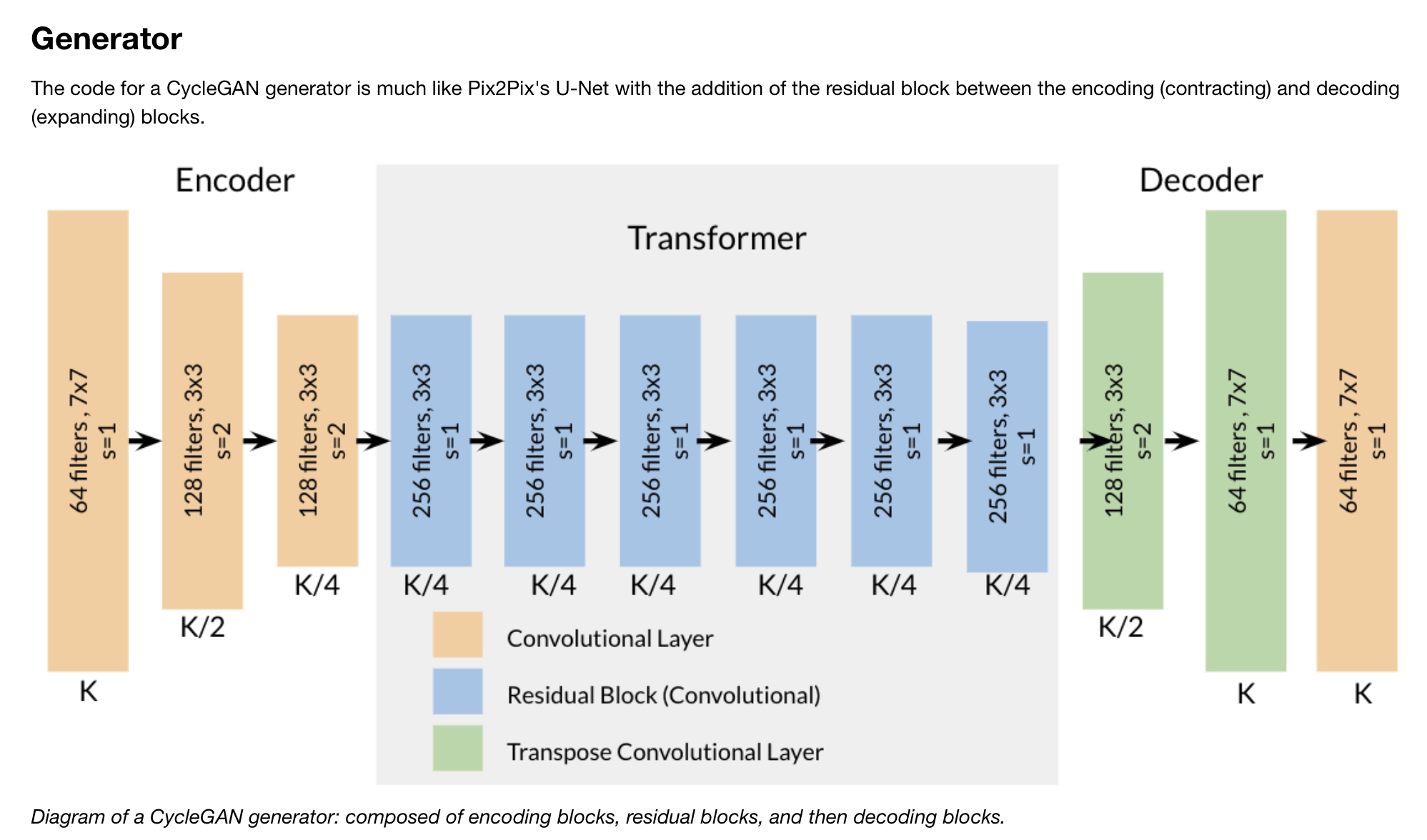
CycleGAN has two generator models (and two PatchGAN discriminators), one to transfer from one style to another and the other model going the opposite way. Therefore they form a cycle. The generators look very similar to a U-Net structure + bottleneck section interconnected with skip connections of DCGAN.
Generator
Loss Terms
All loss terms have to be applied to both of the two generators ⇒ 6 loss terms in the entire loss function!
Adversarial Loss - Squared Loss
We use least square loss in adversarial loss term for CycleGAN because
- Least square do not have extreme behaviors of vanishing gradient problem like BCE loss
- gradient is only flat when prediction is exactly correct
- It is the easiest function to calculate and optimize if we want to bring fake close to real (it considers outliers)
Discriminator Loss:
Generator Loss:
Cycle Consistency
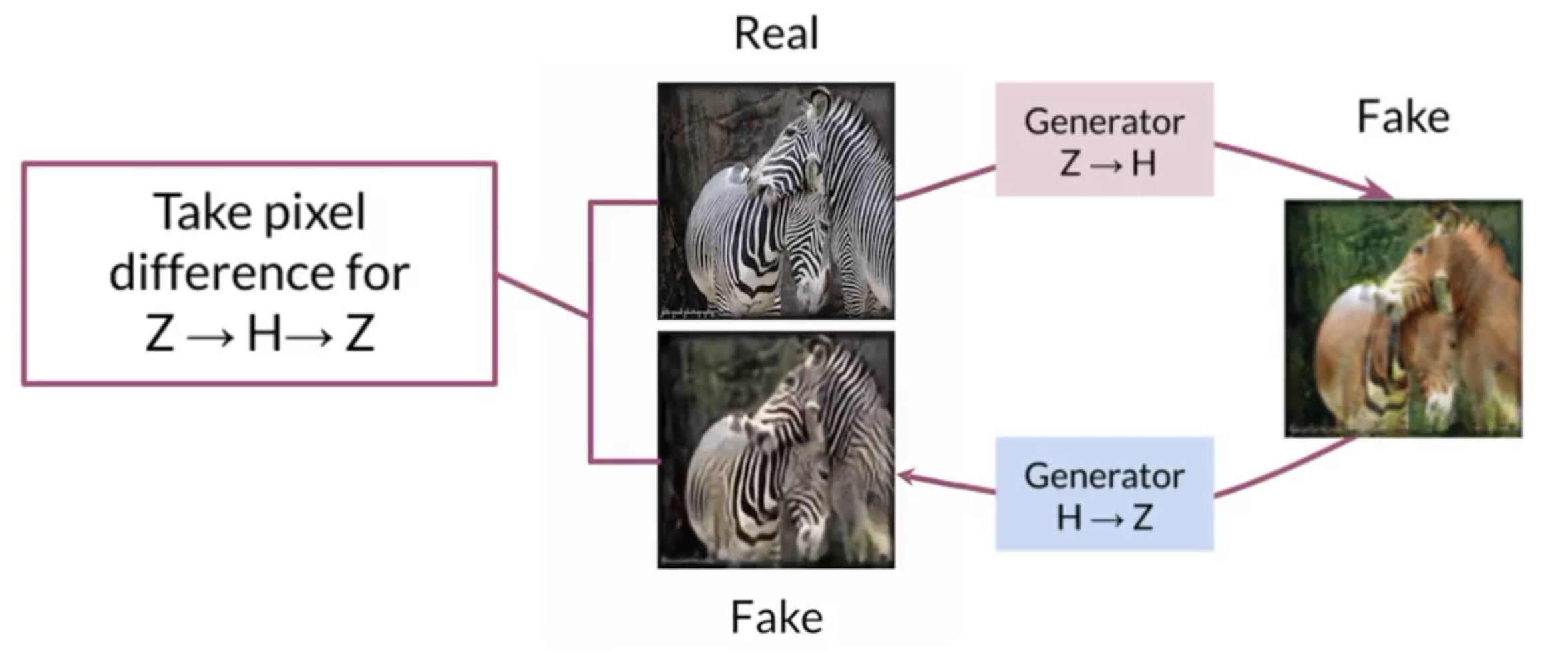
We want the cycle generation to be similar to the original one, only style should have changed so it is appropriate to take the pixel distance.
Ah, plus we also want a two-way cycle consistency so the entire term should be
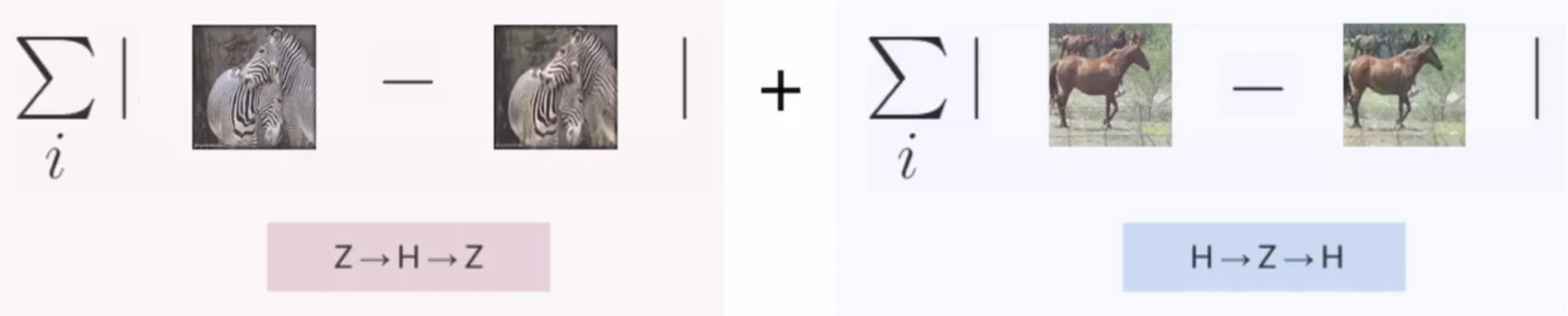
Identity Loss
Additional, optionally added loss term added to the loss function
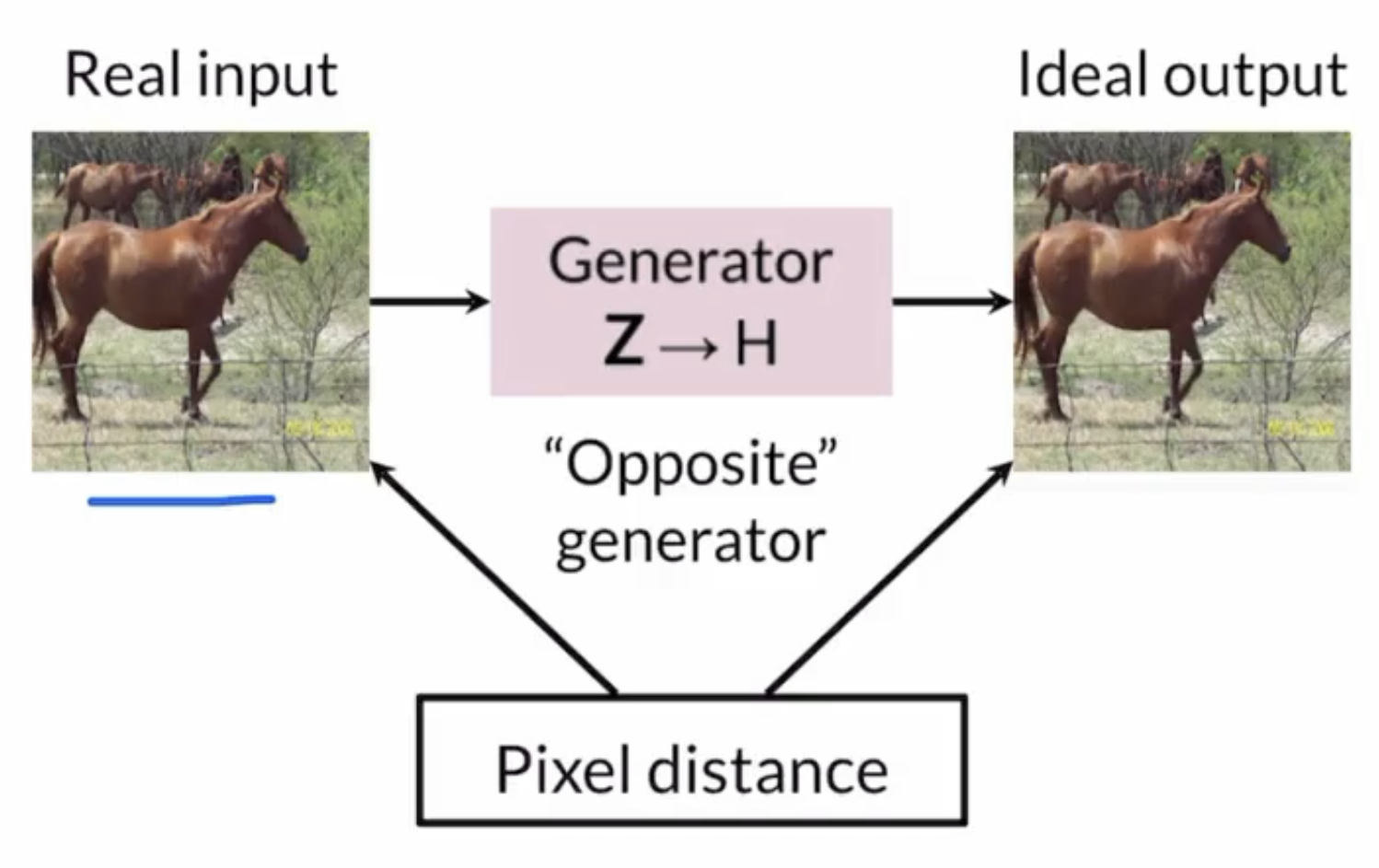
If we put horse into a zebra-to-horse translator, we would expect the horse to come out still as a horse. This technique:
- Discourages Z ⇒ H mapping to distort color
- is two way as well, just like the cycle consistency loss term
